Proceso de extracción de noticias mediante scraping en el Diario La Discusión
Sistema de scraping para extraer noticias, enlaces y contenido del Diario La Discusión.
última Prueba del script - 03 / 03 / 2022
Este script es un extractor de datos (scraping), en este caso, extraje el contenido del diario(periódico) https://www.ladiscusion.cl, que es un diario de mi ciudad, este scraping se separa en dos partes:
Antes de empezar revisamos robots.txt y verificamos los permisos que nos otorga el diario.
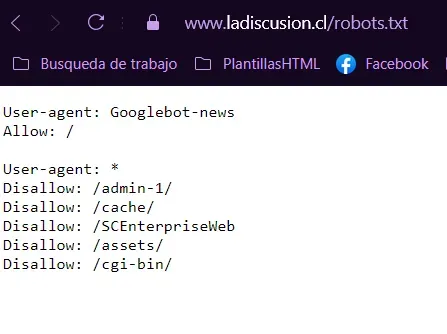
una vez listo, continuamos.
Primer paso - Extracción y creación de dataframes con los links de las noticias por categoria de la barra de navegación.
El script crea dos carpetas, data y data_content, en la carpeta data se almacenarán en un dataframe las categorías con los links y en data_content se almacenará el contenido.
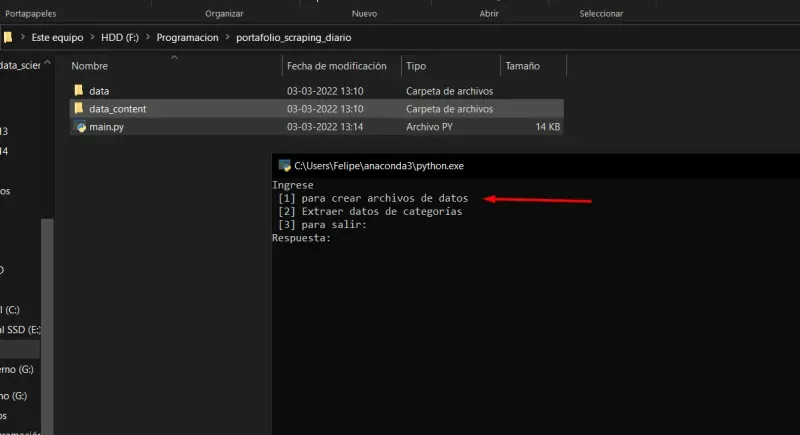
El primer paso para ocupar el script, es utilizar la primera opción:
- Una vez ingresado el comando [1], nos saldrá lo siguiente
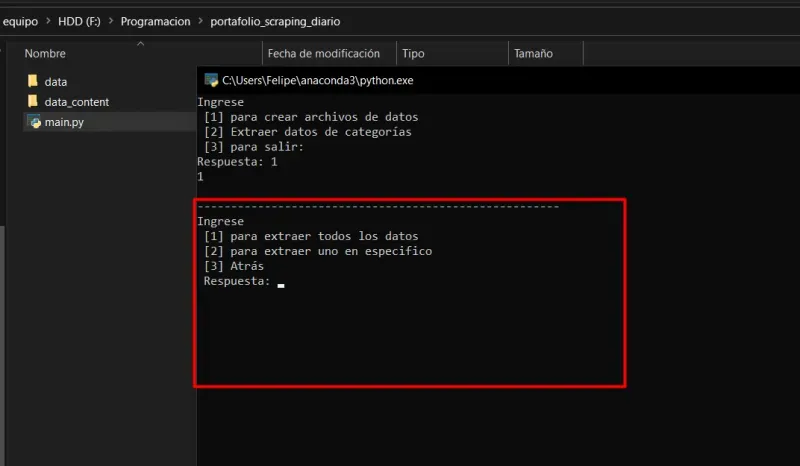
Si se coloca el comando 1, comenzará a scrapear todos los links de la barra de navegación
Sin embargo, la opción 2, nos permite scrapear solo los datos que nosotros querramos, para demostración pondré fotos de la opción 2.
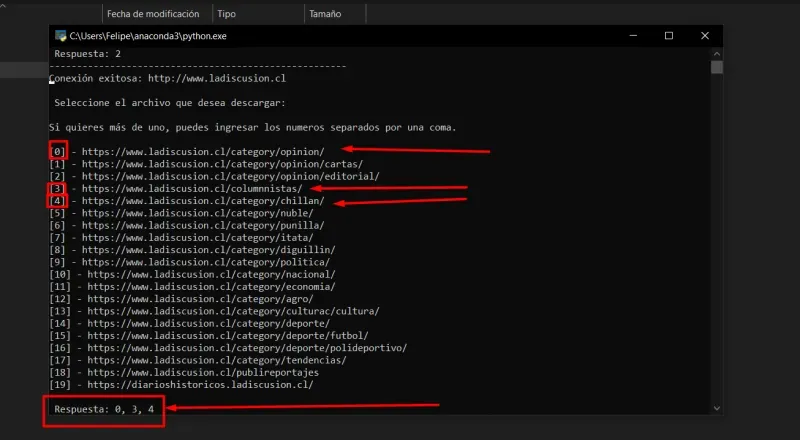
- En el caso anterior, ingresé que solo quiero el 0, el 3 y el 4. Posteriormente corrí el codigo y comenzó a generar las tablas
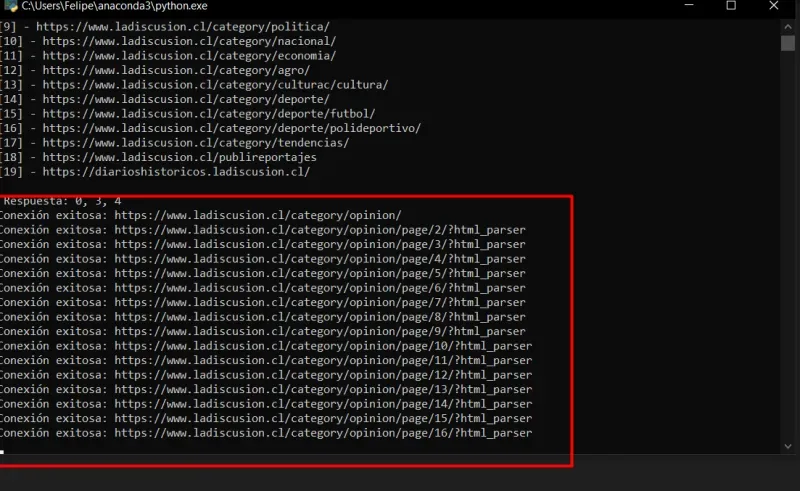
Una vez terminado el primer proceso.
- Tendremos la carpeta data con los dataframes.
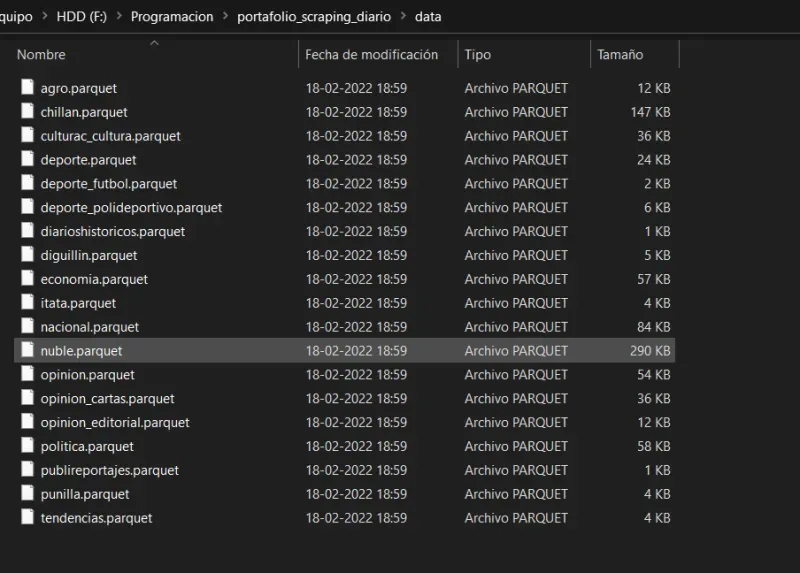
- aquí un vistazo del primer dataframe
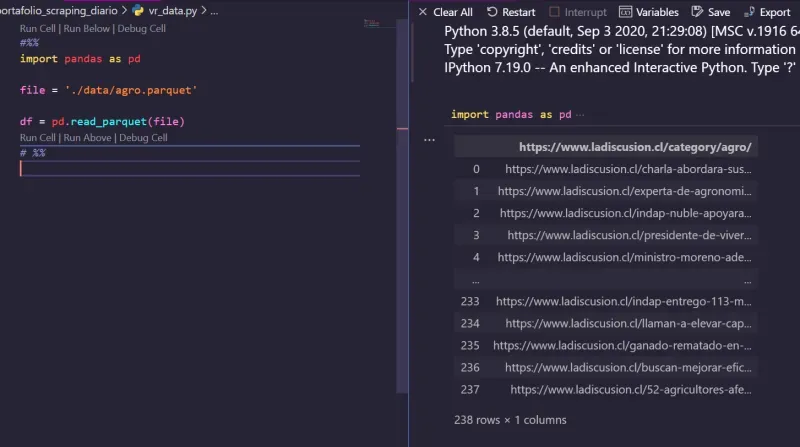
Segundo paso - Creación de dataframes con el Titulo - Hora - Contenido - Subtitulos
- Con el primer paso ya tendrémos todos los links de noticias de la pagina que se encontraban a la fecha de ejecución del script.
- El siguiente paso es sencillo.
- En el menú del script se encuentra la opción [2].
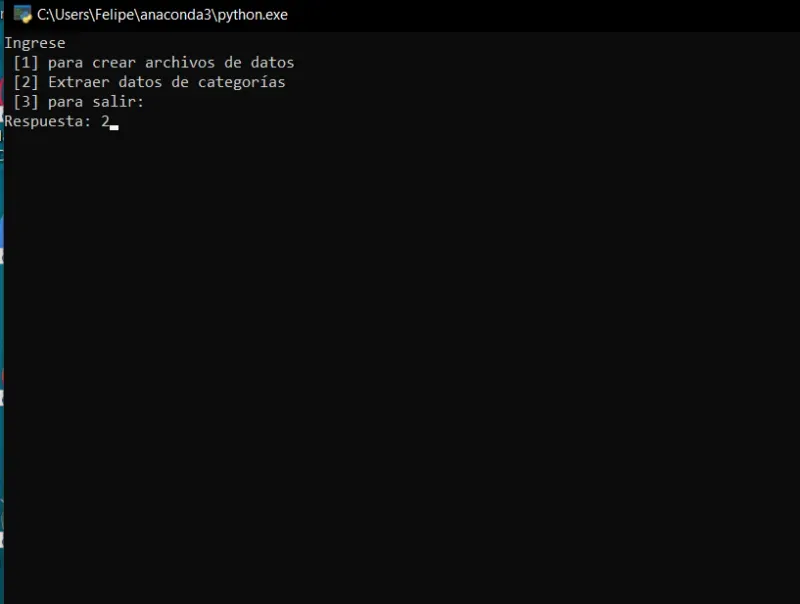
- Esta opción nos despliega otro menú, donde utilizará todos los links que se encuentran en los archivos de la carpeta data.
- opción [1], para hacerlos con todos
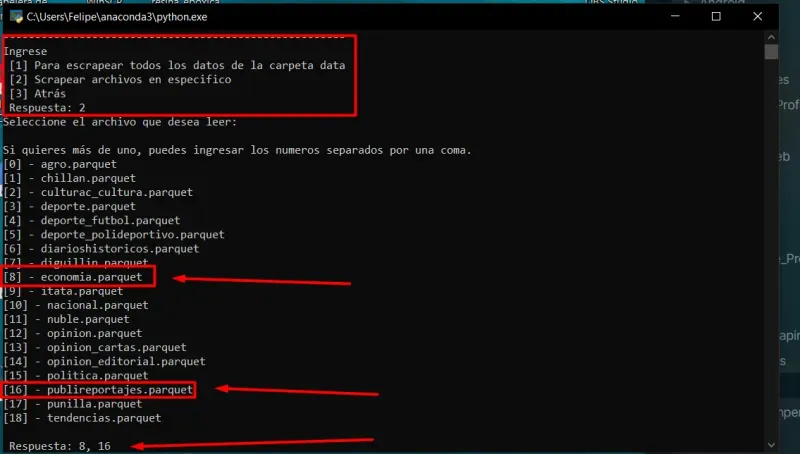
- opción [2], para scrapear archivos en especifico
- Utilizaré el dos a modo de prueba.
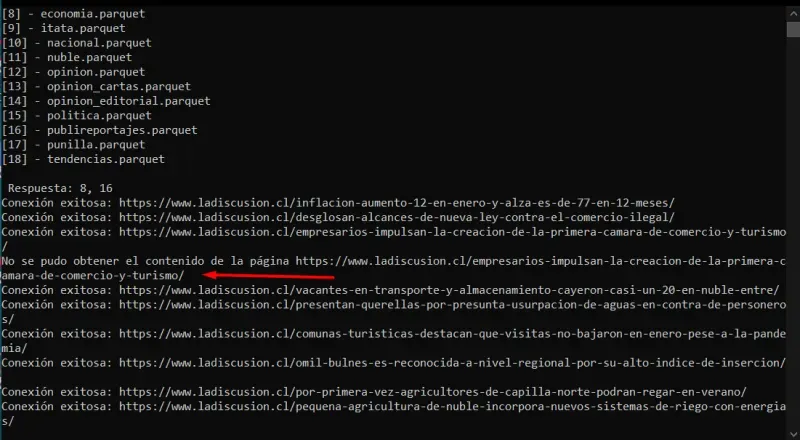
- podemos observar que algunos links no pueden abrise, sin embargo el script continúa.
- una vez terminado, en nuestra carpeta data_content tendrémos los dataframes y contenido listos para su manipulación
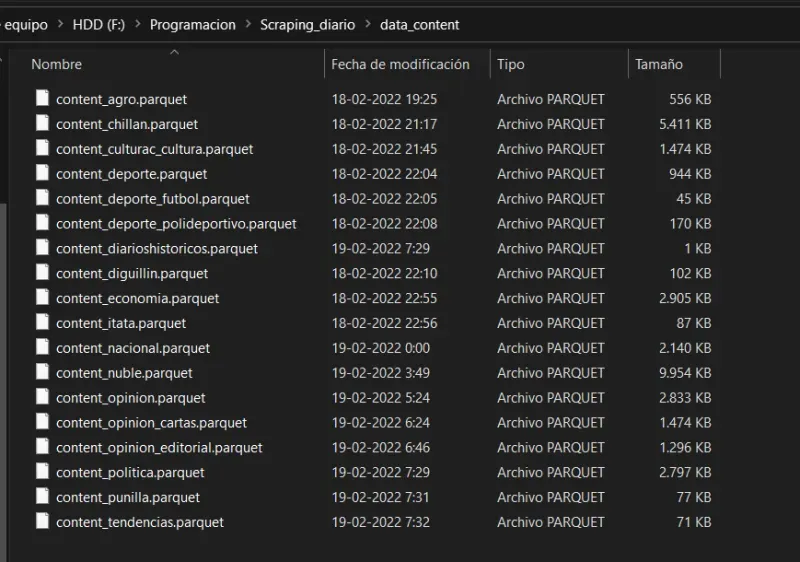
-Miraremos el primero como ejemplo de dataframe
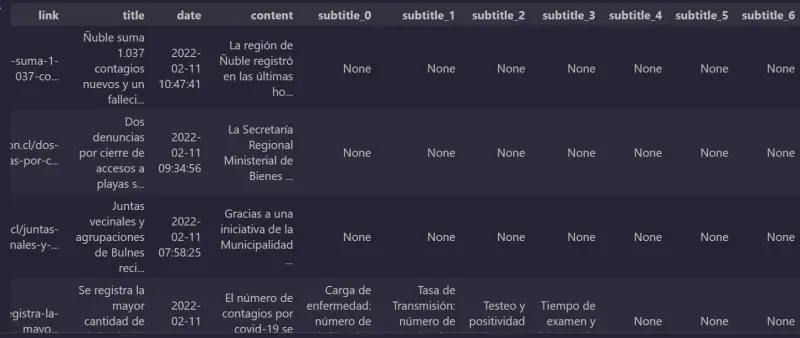
- el
df.info()también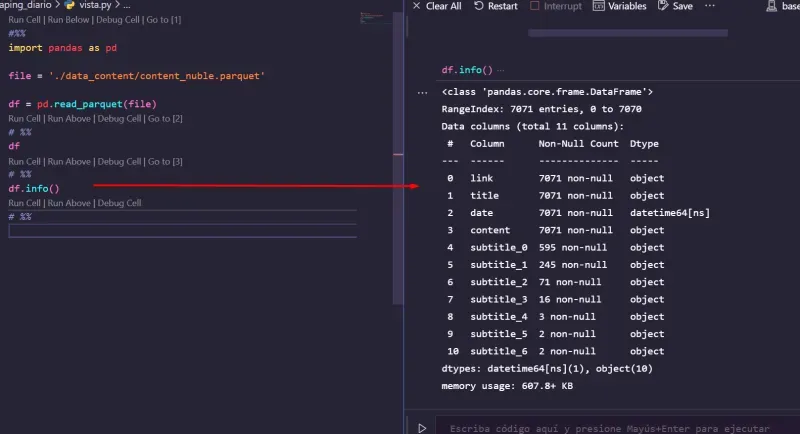
Duración del scraping
- 40 minutos, Primera parte.
- 10 horas, Segunda parte.
Aspectos a optimizar
- Se puede utilizar hilos para que el tiempo de scraping disminuya, haciendo scraping en paralelo.
- Se pueden capturar los archivos los cuales no hizo get request, para un scraping independiente.